Summarizing Videos using Concentrated Attention and Considering the Uniqueness and Diversity of the Video Frames
Περίληψη
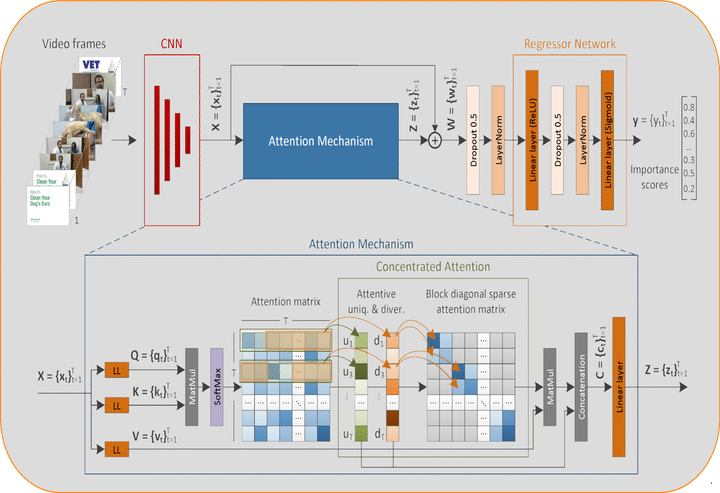
Σε αυτήν την εργασία, περιγράφουμε μια καινούργια μέθοδο για τη δημιουργία περιλήψεων βίντεο χωρίς επίβλεψη. Για να ξεπεραστούν οι περιορισμοί των υφιστάμενων προσεγγίσεων δημιουργίας περιλήψεων χωρίς επίβλεψη, σχετικά με την ασταθή εκπαίδευση των Generator-Discriminator αρχιτεκτονικών, τη χρήση RNNs για τη μοντελοποίηση εξαρτήσεων μεγάλης εμβέλειας των καρέ και την ικανότητα παραλληλοποίησης της εκπαίδευσης αρχιτεκτονικών που βασίζονται σε RNNs, η μέθοδος μας βασίζεται αποκλειστικά στη χρήση ενός μηχανισμού αυτοπροσοχής για την εκτίμηση της σπουδαιότητας των καρέ του βίντεο. Αντί να μοντελοποιούμε απλώς τις εξαρτήσεις των καρέ με βάση την καθολική προσοχή, η μέθοδός μας ενσωματώνει έναν μηχανισμό συγκεντρωμένης προσοχής που είναι σε θέση να εστιάζει σε μη επικαλυπτόμενα μπλοκ στην κύρια διαγώνιο του πίνακα προσοχής και να εμπλουτίζει την υπάρχουσα πληροφορία εξάγοντας και αξιοποιώντας γνώση σχετικά με τη μοναδικότητα και την ποικιλομορφία των σχετικών καρέ του βίντεο. Με αυτόν τον τρόπο, η μέθοδός μας κάνει καλύτερες εκτιμήσεις σχετικά με τη σημαντικότητα διαφορετικών τμημάτων του βίντεο και μειώνει δραστικά τον αριθμό των παραμέτρων του δικτύου. Πειραματικές αξιολογήσεις που χρησιμοποιούν δύο σύνολα δεδομένων (SumMe και TVSum) δείχνουν την ανταγωνιστικότητα της προτεινόμενης μεθόδου έναντι άλλων state-of-the-art προσεγγίσεων δημιουργίας περιλήψεων χωρίς επίβλεψη και καταδεικνύουν την ικανότητά της να παράγει περιλήψεις βίντεο που είναι πολύ κοντά στις ανθρώπινες προτιμήσεις. Μια μελέτη αφαίρεσης που επικεντρώνεται στα προτεινόμενα δομικά στοιχεία, ειδικότερα τη χρήση της συγκεντρωμένης προσοχής σε συνδυασμό με εκτιμήσεις σχετικά με τη μοναδικότητα και την ποικιλομορφία των πλαισίων, δείχνει τη σχετική συνεισφορά τους στη συνολική απόδοση.
Γεώργιος Μπαλαούρας
Data Scientist
Τα ερευνητικά μου ενδιαφέροντα περιλαμβάνουν μεθόδους επεξεργασίας και ανάλυσης πολυμέσων.