Combining Global and Local Attention with Positional Encoding for Video Summarization
Abstract
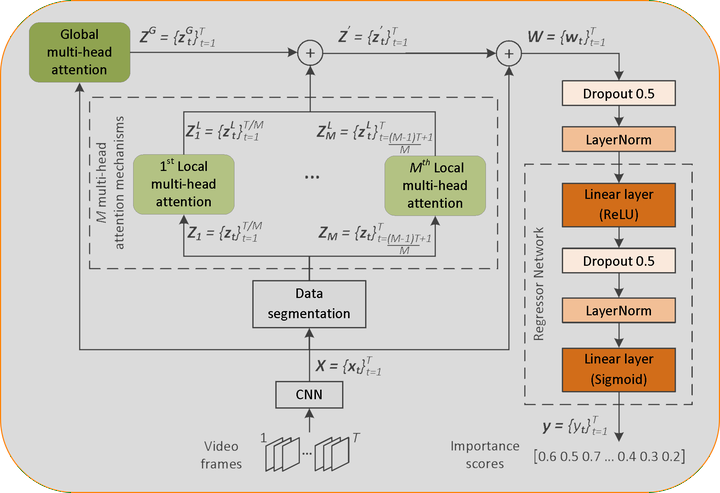
This paper presents a new method for supervised video summarization. To overcome drawbacks of existing RNN-based summarization architectures, that relate to the modeling of long-range frames' dependencies and the ability to parallelize the training process, the developed model relies on the use of self-attention mechanisms to estimate the importance of video frames. Contrary to previous attention-based summarization approaches that model the frames' dependencies by observing the entire frame sequence, our method combines global and local multi-head attention mechanisms to discover different modelings of the frames' dependencies at different levels of granularity. Moreover, the utilized attention mechanisms integrate a component that encodes the temporal position of video frames - this is of major importance when producing a video summary. Experiments on two datasets (SumMe and TVSum) demonstrate the effectiveness of the proposed model compared to existing attention-based methods, and its competitiveness against other state-of-the-art supervised summarization approaches. An ablation study that focuses on our main proposed components, namely the use of global and local multi-head attention mechanisms in collaboration with an absolute positional encoding component, shows their relative contributions to the overall summarization performance.
Georgios Balaouras
Data Scientist
My research interests include Computer Vision with a healthy pinch of problem solving.