Abstract
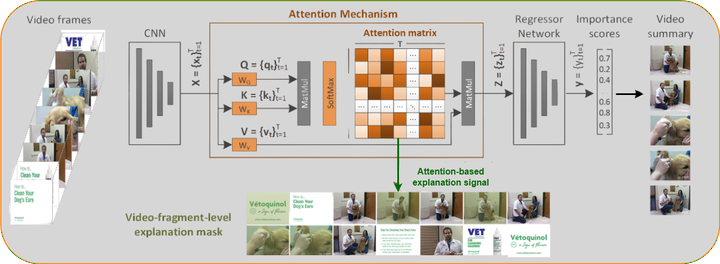
In this paper we propose a method for explaining video summarization. We start by formulating the problem as the creation of an explanation mask which indicates the parts of the video that influenced the most the estimates of a video summarization network, about the frames' importance. Then, we explain how the typical analysis pipeline of attention-based networks for video summarization can be used to define explanation signals, and we examine various attention-based signals that have been studied as explanations in the NLP domain. We evaluate the performance of these signals by investigating the video summarization network’s input-output relationship according to different replacement functions, and utilizing measures that quantify the capability of explanations to spot the most and least influential parts of a video. We run experiments using an attention-based network (CA-SUM) and two datasets (SumMe and TVSum) for video summarization. Our evaluations indicate the advanced performance of explanations formed using the inherent attention weights, and demonstrate the ability of our method to explain the video summarization results using clues about the focus of the attention mechanism.
Georgios Balaouras
Data Scientist
My research interests include Computer Vision with a healthy pinch of problem solving.